Since the Google took over lives and branded a verb for searching as Googling, making a search engine is considered cool thing. I have crossed over search engines several times in my life. Even I worked in a company that was I guess pretending to build search engine (I was there just one month, when I realized they are not serious). But also I got some background on some text mining courses (both at Coursera and at the University of Manchester) and I came to a point of my research where I had to build search engine. Not many people today are building search engine from the scratch, since there are several engine libraries out there and one of the most famous one is Apache Lucene. I will show here how to build some simple search engine on Lucene. However, there are many Lucene tutorials and books. Some of them are too long, and other are not explaining background, just showing code. I would like to make some balance here by also describing some principles, but not too deep in details. So here we go.

Search engine – basics
Search engine is a piece of software that helps users find in some data store the most relevant document as fast as possible. More correct name for the process of finding right information from data store is information retrieval. By data store we mean something that stores documents filled with some information. It can be a hard disk with PDF, TXT and Word documents it can be a database, both relational or non relational or some network with web pages. Information retrieval is different from information extraction. Information retrieval is about getting the right document. User has then to read document and find the information of interest. Information extraction is about extracting information and finding the right piece of information the user is looking for, so he doesn’t need to read document, or even open it to find it. There is a way how to create information extraction search using information retrieval and in some sort I will show it here as well.
Information retrieval algorithm basics
To find the most relevant document in the document set, search engines or information retrieval engines are using some interesting data structures and algorithms. Lets discus intuition how search engine might work. What is the thing that distinguishes relevant documents from non relevant? Intuition would say if and how many times document mentioned the searched terms. This is one of the first algorithms that was used in information retrieval and it is called term-frequency algorithm (TF). Here, for each document is built frequency table. In frequency table each word that can be found in document has a number how many times it occurred in that document. So if word example in document occurred 3 times it will have term frequency 3. However there are some other tweaks to this, for example:
- Boolean “frequencies”: tf(t,d) = 1 if t occurs in d and 0 otherwise;
- logarithmically scaled frequency: tf(t,d) = log (f(t,d) + 1);
- augmented frequency, to prevent a bias towards longer documents, e.g. raw frequency divided by the maximum raw frequency of any term in the document:
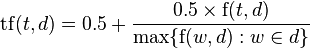
However, this will give some pretty good results in some cases, but there are cases in which this won’t work. For example if a search query contains some generally often word. Almost all document would contain it, which would mean that all documents are relevant. The query would contain more words, while most of the not frequent words are more important in query than the often one. And since the frequency of often ones are higher than these infrequent ones, frequent words will be taken more in account. To solve this problem, new algorithm was introduced, called term frequency-inverse document frequency (TF-IDF). This algorithm weights more words in query that are less frequent and sort document by word frequency and how frequent word is in all documents. We already know how term frequency is calculated (see above).
Inverse document frequency is a measure of whether the term is common or rare across all documents. It is obtained by dividing the total number of documents by the number of documents containing the term, and then taking the logarithm of that quotient.
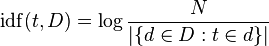
Then tf–idf is calculated as

TF-IDF is a measure for one document. It is weight of term regarding some document and some document store. But how is measured what documents are the most relevant according to search query. You may calculate these weights for each word in query and document in the document store. This will give some quite fine results. However, this have some minor problems that are solved using cosine similarity measure.
Cosine similarity is a measure of similarity between two vectors of an inner product space that measures the cosine of the angle between them. Since cosine 0° is 1, if two vectors have same angle, they are the best match.
The cosine of two vectors can be derived by using the Euclidean dot product formula:
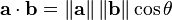
Given two vectors of attributes, A and B, the cosine similarity, cos(θ), is represented using a dot product and magnitude as
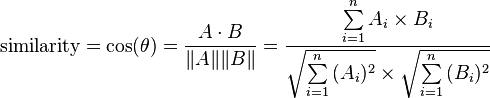
Dot product is calculated between tf-idf values of query, which is viewed as one document and some other document in data set. This is currently one of the state-of-the-art techniques for scoring relevance of the text.
Little tweaks
Cosine similarity is a great measure if all parts of documents should be weighted same way. However this is not always the case. Sometimes it is more relevant if document has more similar title to the query, but in text it does not use the exact words as much as maybe some other document which does not have the search terms in title. Or maybe it is important to have search terms in abstract, tables etc.
To solve this problem, each part of document can be seen as separate document. Then for this would be calculated tf-idf and cosine similarity. Each result can be multiplied with some number to boost or downgrade result in the search results. For each document is calculated maximum of the cosine similarities of document parts and this is used as document similarity in the final results. This process is called index boosting.
Does this seems complicated? Well a bit probably. Especially there these systems need to be very fast and optimized. There are some special file and data structures used for optimization of index. However, there are some frameworks which implement all these, so programmer has to think only about important thing. Probably the most popular framework is Apache Lucene, supported by Apache foundation.

Lucene framework
So enough with the algorithm background. That is important, because you cannot build search engine not knowing what are you doing, but lets talk code. Apache Lucene is a free/open source information retrieval software library, originally created in Java by Doug Cutting. It is supported by the Apache Software Foundation and is released under the Apache Software License. I will here explain a bit code I wrote for my research in information extraction from PMC tables. I have build another piece of software that was extracting tables from clinical biomedical documents from PubMedCentral and making from simple tables documents containing one cell. The whole project of my search engine can be found on GitHub (https://github.com/nikolamilosevic86/LuceneCellSearch). However, what I write is reflection of today’s state (24. april 2014.), and due it is ongoing project, github code might be changed.
Typical document in my data store is xml file that looks like this:
So each document contains several sections, that will later be used for index boosting.
Document indexing is done using performIndexing method
public static void performIndexing(String docsPath, String indexPath,
boolean create) {
final File docDir = new File(docsPath);
if (!docDir.exists() || !docDir.canRead()) {
System.out
.println("Document directory '"
+ docDir.getAbsolutePath()
+ "' does not exist or is not readable, please check the path");
System.exit(1);
}
Date start = new Date();
try {
System.out.println("Indexing to directory '" + indexPath + "'...");
Directory dir = FSDirectory.open(new File(indexPath));
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_47);
IndexWriterConfig iwc = new IndexWriterConfig(Version.LUCENE_47,
analyzer);
if (create) {
// Create a new index in the directory, removing any
// previously indexed documents:
iwc.setOpenMode(OpenMode.CREATE);
} else {
// Add new documents to an existing index:
iwc.setOpenMode(OpenMode.CREATE_OR_APPEND);
}
IndexWriter writer = new IndexWriter(dir, iwc);
Indexer.indexDocs(writer, docDir);
writer.close();
Date end = new Date();
System.out.println(end.getTime() - start.getTime()
+ " total milliseconds");
} catch (IOException e) {
System.out.println(" caught a " + e.getClass()
+ "\n with message: " + e.getMessage());
}
}
Here most important class is IndexWriter. In this case he creates index in file, where specified in path. However index can be created on the other sources like database. The indexing is not explained here, there is an method IndexDoc, which actually does the work. However line Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_47); initiates analyzer which does standard actions creating tf-idf and cosine similarity.
static void indexDocs(IndexWriter writer, File file) throws IOException {
// do not try to index files that cannot be read
if (file.canRead()) {
if (file.isDirectory()) {
String[] files = file.list();
// an IO error could occur
if (files != null) {
for (int i = 0; i < files.length; i++) {
indexDocs(writer, new File(file, files[i]));
}
}
} else {
try {
// make a new, empty document
Document doc = new Document();
// Add the path of the file as a field named "path". Use a
// field that is indexed (i.e. searchable), but don't
// tokenize
// the field into separate words and don't index term
// frequency
// or positional information:
Field pathField = new StringField("path", file.getPath(),
Field.Store.YES);
doc.add(pathField);
// Add the last modified date of the file a field named
// "modified".
// Use a LongField that is indexed (i.e. efficiently
// filterable with
// NumericRangeFilter). This indexes to milli-second
// resolution, which
// is often too fine. You could instead create a number
// based on
// year/month/day/hour/minutes/seconds, down the resolution
// you require.
// For example the long value 2011021714 would mean
// February 17, 2011, 2-3 PM.
doc.add(new LongField("modified", file.lastModified(),
Field.Store.NO));
@SuppressWarnings("resource")
BufferedReader reader = new BufferedReader(new FileReader(
file.getPath()));
String line = null;
String xml = "";
while ((line = reader.readLine()) != null) {
if (line.contains("JATS-archivearticle1.dtd")
|| line.contains("archivearticle.dtd"))
continue;
xml += line + '\n';
}
String attribute = "";
String value = "";
String documentTitle = "";
String tableTitle = "";
String tableFooter = "";
String PMC = "";
String tableOrder = "";
try {
DocumentBuilderFactory factory = DocumentBuilderFactory
.newInstance();
factory.setNamespaceAware(true);
factory.setValidating(false);
DocumentBuilder builder = factory.newDocumentBuilder();
InputSource is = new InputSource(new StringReader(xml));
org.w3c.dom.Document parse = builder.parse(is);
attribute = parse.getElementsByTagName("attribute")
.item(0).getTextContent();
value = parse.getElementsByTagName("value").item(0)
.getTextContent();
tableTitle = parse.getElementsByTagName("tableName")
.item(0).getTextContent();
tableFooter = parse.getElementsByTagName("tableFooter")
.item(0).getTextContent();
documentTitle = parse
.getElementsByTagName("DocumentTitle").item(0)
.getTextContent();
PMC = parse.getElementsByTagName("PMC").item(0)
.getTextContent();
tableOrder = parse.getElementsByTagName("tableOrder").item(0)
.getTextContent();
} catch (Exception ex) {
ex.printStackTrace();
}
// Add the contents of the file to a field named "contents".
// Specify a Reader,
// so that the text of the file is tokenized and indexed,
// but not stored.
// Note that FileReader expects the file to be in UTF-8
// encoding.
// If that's not the case searching for special characters
// will fail.
TextField att = new TextField("attribute", attribute,
Field.Store.YES);
att.setBoost(1.1f);
TextField val = new TextField("value", value,
Field.Store.YES);
val.setBoost(1.1f);
TextField tabname = new TextField("tableName", tableTitle,
Field.Store.YES);
tabname.setBoost(1.5f);
TextField tabfoot = new TextField("tableFooter",
tableFooter, Field.Store.YES);
tabfoot.setBoost(1.2f);
TextField tableOrd = new TextField("tableOrder",
tableOrder, Field.Store.YES);
TextField doctitle = new TextField("DocumentTitle",
documentTitle, Field.Store.YES);
doctitle.setBoost(1.0f);
TextField pmc = new TextField("PMC", PMC, Field.Store.YES);
pmc.setBoost(1.0f);
doc.add(att);
doc.add(val);
doc.add(tabname);
doc.add(tabfoot);
doc.add(doctitle);
doc.add(pmc);
doc.add(tableOrd);
if (writer.getConfig().getOpenMode() == OpenMode.CREATE) {
// New index, so we just add the document (no old
// document can be there):
System.out.println("adding " + file);
writer.addDocument(doc);
} else {
// Existing index (an old copy of this document may have
// been indexed) so
// we use updateDocument instead to replace the old one
// matching the exact
// path, if present:
System.out.println("updating " + file);
writer.updateDocument(new Term("path", file.getPath()),
doc);
}
}
}
}
This part actually initiates classes needed for indexing, reads file and calculates weights as needed. The major part here is reading document and assigning Boost parameter. We here decide which part of document is weighted more then the others. Fields we want to be analyzed as text, with all processing like stemming, stopword filtering we put in TextField, however we put path in StringField and it won’t be analyzed with text processing algorithms. We also use default English stopwords.
For search we use different method called perform Search
public static void PerformSearch(String queries, String index,
String queryString, int repeat, int hitsPerPage, boolean raw,
String field) throws IOException, ParseException {
IndexReader reader = DirectoryReader.open(FSDirectory.open(new File(
index)));
IndexSearcher searcher = new IndexSearcher(reader);
// :Post-Release-Update-Version.LUCENE_XY:
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_47);
BufferedReader in = null;
if (queries != null) {
in = new BufferedReader(new InputStreamReader(new FileInputStream(
queries), "UTF-16"));
} else {
in = new BufferedReader(new InputStreamReader(System.in, "UTF-16"));
}
// :Post-Release-Update-Version.LUCENE_XY:
MultiFieldQueryParser parser = new MultiFieldQueryParser(
Version.LUCENE_47, new String[] { "attribute", "value",
"tableName", "tableFooter", "DocumentTitle" }, analyzer);
while (true) {
if (queries == null && queryString == null) { // prompt the user
System.out.println("Enter query: ");
}
String line = queryString != null ? queryString : in.readLine();
if (line == null || line.length() == -1) {
break;
}
line = line.trim();
if (line.length() == 0) {
break;
}
Query query = parser.parse(line);
System.out.println("Searching for: " + query.toString(field));
if (repeat > 0) { // repeat & time as benchmark
Date start = new Date();
for (int i = 0; i < repeat; i++) {
searcher.search(query, null, 100);
}
Date end = new Date();
System.out.println("Time: " + (end.getTime() - start.getTime())
+ "ms");
}
Searcher.doPagingSearch(in, searcher, query, hitsPerPage, raw,
queries == null && queryString == null);
if (queryString != null) {
break;
}
}
reader.close();
}
Here we put our query and where our index file is located. So we can create in same or in different processes or application indexer and search interface. Also here we can put how many hits per page we want to see and some parameters like that. IndexSearcher class performs the search. We also need a query parser, and since we have multiple fields in our documents we use MultiQueryParser. However, the search is performed in doPagingSearch method. I have modified a search a bit. In the original you would get results per document, but my search was summing up all documents that are pointing in the same PMC document and same table. Also some little boosting is done if multiple documents are showing same document. Only document number and table order is shown. Here is the code of doPagingSearch method
public static void doPagingSearch(BufferedReader in,
IndexSearcher searcher, Query query, int hitsPerPage, boolean raw,
boolean interactive) throws IOException {
// Collect enough docs to show 5000 pages
TopDocs results = searcher.search(query, 5000 * hitsPerPage);
ScoreDoc[] hits = results.scoreDocs;
int numTotalHits = results.totalHits;
//System.out.println(numTotalHits + " total matching documents");
int start = 0;
int end = Math.min(numTotalHits, hitsPerPage);
while (true) {
if (end > hits.length) {
System.out
.println("Only results 1 - " + hits.length + " of "
+ numTotalHits
+ " total matching documents collected.");
System.out.println("Collect more (y/n) ?");
String line = in.readLine();
if (line.length() == 0 || line.charAt(0) == 'n') {
break;
}
hits = searcher.search(query, numTotalHits).scoreDocs;
}
HashMap<String,Document> res = new HashMap<String,Document>();
HashMap<String,ScoreDoc2> scoreres = new HashMap<String,ScoreDoc2>();
for(ScoreDoc hit : hits)
{
Document doc = searcher.doc(hit.doc);
String pmc = doc.get("PMC");
String tableOrder = doc.get("tableOrder");
if(res.get(pmc+tableOrder)==null)
{
res.put(pmc+tableOrder, doc);
scoreres.put(pmc+tableOrder, new ScoreDoc2(hit));
}
else
{
ScoreDoc2 score = (ScoreDoc2) scoreres.get(pmc+tableOrder);
score.score+=hit.score;
score.numOfDocs++;
}
}
int k= 0;
hits = new ScoreDoc[scoreres.size()];
for (Entry<String, ScoreDoc2> mapEntry : scoreres.entrySet()) {
hits[k] = mapEntry.getValue();
hits[k].score = (float) (hits[k].score / (mapEntry.getValue().numOfDocs*0.9));
k++;
}
System.out.println(k + " total matching documents");
k = 0;
List arr = Arrays.asList(hits);
Collections.sort(arr, new Comparator() {
public int compare(ScoreDoc b1, ScoreDoc b2) {
if(b1.score>b2.score) return -1;
else return 1;
}
});
k=0;
hits = new ScoreDoc[arr.size()];
for(ScoreDoc ar :arr)
{
hits[k] = ar;
k++;
}
end = Math.min(hits.length, start + hitsPerPage);
for (int i = start; i < end; i++) { if (raw) { // output raw format System.out.println("doc=" + hits[i].doc + " score=" + hits[i].score); continue; } Document doc = searcher.doc(hits[i].doc); String path = doc.get("path"); if (path != null) { System.out.println((i + 1) + ". " + path); String pmc = doc.get("PMC"); if(pmc!=null) { System.out.println(" PMC:"+doc.get("PMC")); } String tableNo = doc.get("tableOrder"); if(tableNo!=null) { System.out.println(" Table:"+doc.get("tableOrder")); } String title = doc.get("tableName"); if (title != null) { System.out.println(" tableName: " + doc.get("tableName")); } } else { System.out.println((i + 1) + ". " + "No path for this document"); } } if (!interactive || end == 0) { break; } if (numTotalHits >= end) {
boolean quit = false;
while (true) {
System.out.print("Press ");
if (start - hitsPerPage >= 0) {
System.out.print("(p)revious page, ");
}
if (start + hitsPerPage < numTotalHits) {
System.out.print("(n)ext page, ");
}
System.out
.println("(q)uit or enter number to jump to a page.");
String line = in.readLine();
if (line.length() == 0 || line.charAt(0) == 'q') {
quit = true;
break;
}
if (line.charAt(0) == 'p') {
start = Math.max(0, start - hitsPerPage);
break;
} else if (line.charAt(0) == 'n') {
if (start + hitsPerPage < numTotalHits) {
start += hitsPerPage;
}
break;
} else {
int page = Integer.parseInt(line);
if ((page - 1) * hitsPerPage < numTotalHits) {
start = (page - 1) * hitsPerPage;
break;
} else {
System.out.println("No such page");
}
}
}
if (quit)
break;
end = Math.min(numTotalHits, start + hitsPerPage);
}
}
}
As I told, this method is doing my custom sorting based on TD-IDF and then calculating how many documents are pointing to the same table. First verson was just summing up the results, but that was not the good idea, because table title and footer are repeating in each document. So I implemented my ScoreDoc2, which extends ScoreDoc and adds field which shows number of document pointing to the same table. However, when I had to devide the calculated score, I multiplied number of documents with 0.9, to add some boost to the tables that has results in multiple documents/cells. Also this function prints out the results. This is command line application, however, you may use lucene with web based applications. This app is build with current Lucene version, which is 4.7.1
Conclusion
I hope now you can see how relatively easy can be to build a search engine. There can be a lot of work fine tuning results and making client application (well it has one input field and table of results). It opens quite great possibilities. Now I am thinking about creating Search engine, information extraction and language processing consultancy at some point of my life. However if you prefer done search engine, you may use Solr, which is search engine build on Lucene. However if you want to code, or hardly customize search, or at least do some modification as I did here, Lucene is perfect.
 fighting human bots (using NLP and OCR)")


